.svg)


Update 2,written by Timan, the Interim Hyperscale Lead
In my last update, I wrote about how I went from 0 to 1 — or more accurately, from 0 to 100k TPS. This week, I want to start with a short progress update before diving deeper into how I actually run Hyperscale tests.
An update on my progress
Since the previous update, things have moved quickly. Some days were smooth, others were a grind, which is pretty normal when you’re learning a new codebase and pushing an experimental network to its limits.
Last week, I ran another successful test with the private testing group, confirming the 100k TPS result from before. And this week I managed to reach 250k TPS on a 32-shard setup! A big step forward.
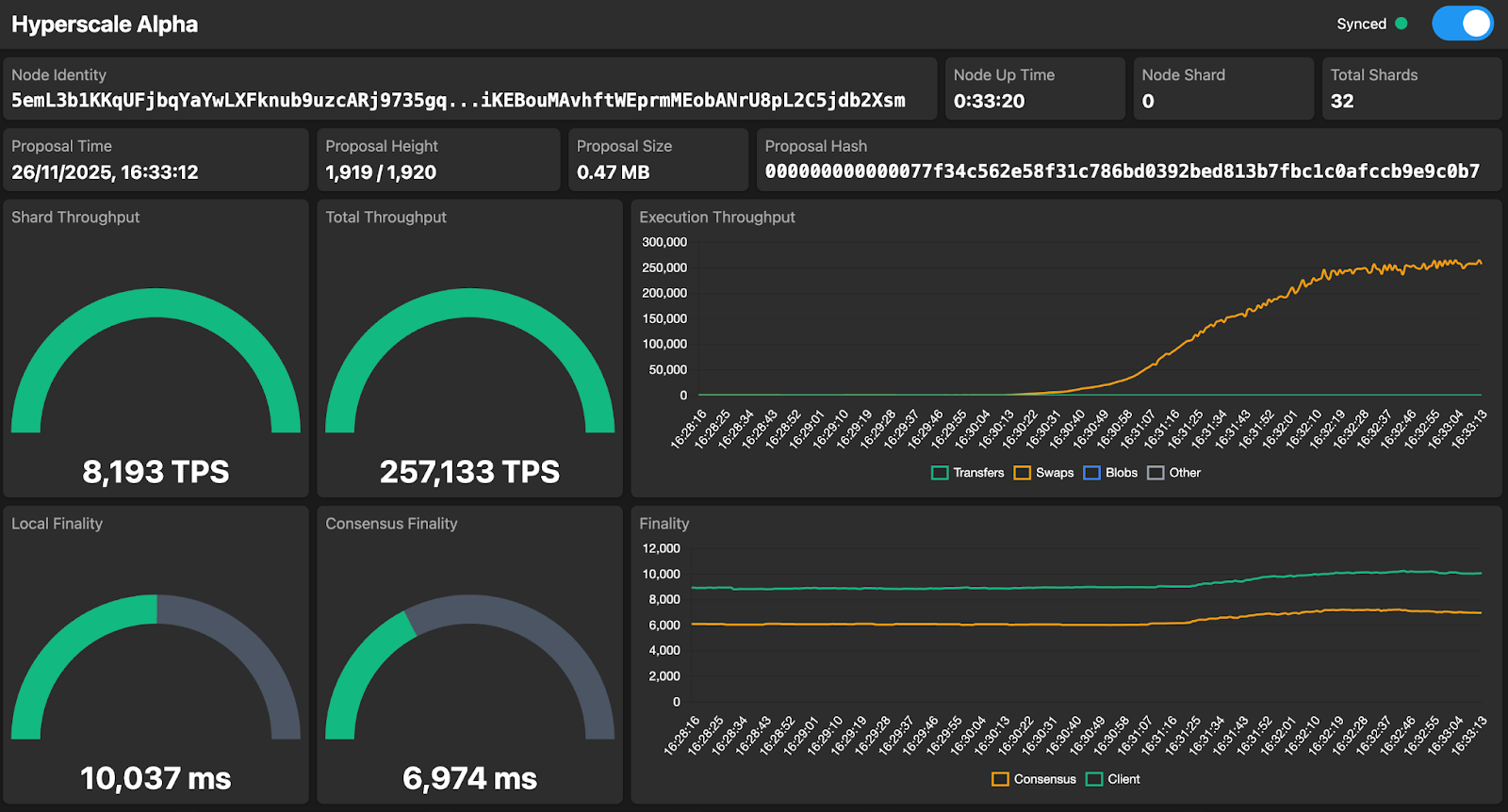
One other benefit of running all these tests is that they force me to learn more of Dan’s codebase in a very hands-on way. I didn’t start by trying to fully understand every detail. That would have taken weeks, if not months. Instead, I chose to start running tests, build intuition through practice, and deepen my understanding step by step. I’m also extremely glad that the main language we used back in university was Java and not one of the older ones; it definitely makes picking up the codebase a lot faster.
Hitting higher TPS numbers is only one part of the story, though; the other part is how those numbers come to life. So let me walk you through the way I run Hyperscale tests.
Running tests in a structured way
After years of working with startups and corporate innovation teams, I’ve learned that running tests, or experiments, in a “business-science” way works incredibly well. It’s not real science, because that would be too slow and too expensive, but it is structured. For every Hyperscale test I run, alone or with others, I fill in an experiment card. On that card, I note the setup — number of nodes, shards, configuration items — along with the goal, the peak TPS, the results, and the next steps.
These experiment cards make it much easier to track progress. Some days are slow, but when I look back at a week of cards, the progress is obvious. It’s also a great way to share updates with the rest of the team.
Different types of tests
I run tests at three different layers.
First, there are the internal tests on my own Hetzner cluster. These nodes are very homogeneous, usually in one or two data centers, and I typically use 3 to 5 nodes per shard.
Then we have the private tests with the private testing group. They bring in a large number of nodes, still mostly data-center grade, but far more geographically spread and with a broader mix of hardware.
Finally, there are the public tests, where everyone can join. Even Timan with his MacBook Air on WiFi and battery.
Each layer has a different purpose.
The internal tests are close to an ideal environment: low nodes-per-shard, controlled infrastructure, consistent hardware. Very similar to how most of our competitors run their own performance tests, with one big difference: these machines are commodity hardware. Four cores, 16 GB RAM, and a 160 GB SSD drive. Less powerful than my own MacBook Air, except I have a lot more of them. That’s one of the things I love about Hyperscale: you don’t need supercomputers. You can use hardware similar to today’s Babylon validators and still scale TPS dramatically.
The private tests focus on robustness under conditions similar to the current Babylon validator set. Most participants in the private tests run data-center nodes, just as most validators do today.
The public tests are the ultimate challenge: can Hyperscale run on every kind of hardware, anywhere in the world?
The learn and confirm feedback loop
Where Dan tested all three configurations in parallel, I decided to first focus on raw throughput. If I can’t hit 500k or 1M TPS internally, I know the private or public group won’t hit it either. Once I’m confident a target TPS is achievable in my internal cluster, I bring in the private testing group to confirm the findings under more realistic conditions.
This creates a continuous feedback loop: learn with internal tests, confirm with private tests. The private group’s setups closely resemble the current Babylon validator environment, so confirmation from that group means a lot.
So what about the public tests? I think they’re super exciting and the ultimate demonstration of Hyperscale. When we’re confidently on track toward 500k to 1M TPS, we will organize one. It will be a powerful way to showcase the stability and robustness of Hyperscale in the wild.
At the same time, we should remember that most other networks do not do public performance tests. Their tests are usually done under far stricter conditions and on much heavier hardware than what I even use internally. So when we do a public test, it should be at the right moment, when it highlights our strengths rather than masking them.
But first, let’s hit 500k tps!